La génération de scénarios est un élément clé dans l’anticipation de l’évolution des risques. Les méthodes d’IA générative constituent une réelle opportunité.
Face à des risques en rapide évolution, l’approche dite historique ne suffit plus. Par historique, on entend la reconduction d’une modélisation du risque qui repose sur des données anciennes. Le classique GLM (modèle linéaire généralisé) obéit à cette logique. L’analyse des sinistres passés sert par exemple à identifier l’impact de différents facteurs sur la fréquence de sinistre ou leur sévérité. Le modèle ainsi obtenu sert à projeter le risque pour les exercices suivants. Parmi les reproches fréquemment émis, on peut taxer cette approche d’être trop fortement tournée vers le passé. La critique n’est pas complètement juste : il n’est pas interdit d’intégrer à ces modèles une tendance qui sera ensuite extrapolée. Par ailleurs, il est tout à fait possible, une fois identifiés les facteurs (notamment environnementaux) qui pèsent sur le risque, de projeter leur évolution et de dépasser une vision statique afin d’anticiper les impacts futurs.
Une approche historique parfois limitée
Cette approche rencontre malgré tout ses limites. Dans le domaine climatique notamment, l’accélération brutale du changement climatique doit nous pousser à envisager des événements qui n’ont jamais encore été rencontrés, ou trop peu pour peser dans les approches statistiques traditionnelles. Les dramatiques conséquences des inondations de Valence en octobre 2024 sont un exemple de situations qui pourraient constituer une nouvelle normalité. Or, le phénomène de goutte froide frappant avec une telle intensité une zone urbaine d’une telle densité, non préparée pour ce type de phénomène, peut être considéré comme une nouveauté. Le glissement de la modélisation actuarielle vers une approche par scénario plutôt qu’une approche purement historique est à présent de plus en plus recommandé. Une philosophie qui prolonge la logique de stress-tests que les régulateurs imposent, mais déborde sur le quotidien des assureurs, puisqu’elle ne concerne plus seulement des phénomènes rares.
Une approche par scénario plus pertinente
Dans une approche par scénario, on définit un certain nombre de conditions initiales et on analyse leur propagation à un système exposé au risque, qu’il s’agisse, suivant la finalité, du portefeuille de l’assureur, d’une sous-population particulière ou de l’économie tout entière. Ces conditions initiales peuvent prendre différentes formes. Dans le domaine des risques naturels, on pense bien entendu aux différents scénarios du Giec, qui fournissent de grandes orientations climatiques plausibles. Pour le secteur de l’assurance, l’enjeu est ensuite de les traduire dans son champ d’action. Lequel ne se borne pas simplement au coût financier des catastrophes, mais intègre aussi l’anticipation des mesures de prévention, d’accompagnement, d’assistance de ses clients. Une question bien plus complexe que la simple évaluation – certes cruciale – d’un montant de capital à opposer au risque, car elle met en jeu la planification du déploiement de moyens techniques et humains.
Le champ des possibles étant particulièrement vaste, la simulation de scénarios stochastiques doit nous permettre d’explorer un nombre plus important de situations et d’apprendre à y faire face. Bien entendu, concevoir un tel générateur de scénarios s’avère particulièrement complexe. C’est là que l’intelligence artificielle (IA) générative émerge comme un bon candidat pour accomplir cette tâche. Son déploiement nécessite néanmoins une forte vigilance : nous ne voulons pas seulement générer des scénarios, nous voulons générer des scénarios plausibles et pertinents. Il faut en effet que l’IA ait appris correctement et ne soit pas simplement entraînée à reproduire des tendances passées.
Deux méthodes principales
Nous rencontrons deux méthodes principales derrière les techniques d’IA génératives. Les generative adversarial networks (GAN, voir figure 1) sont composés de deux blocs.
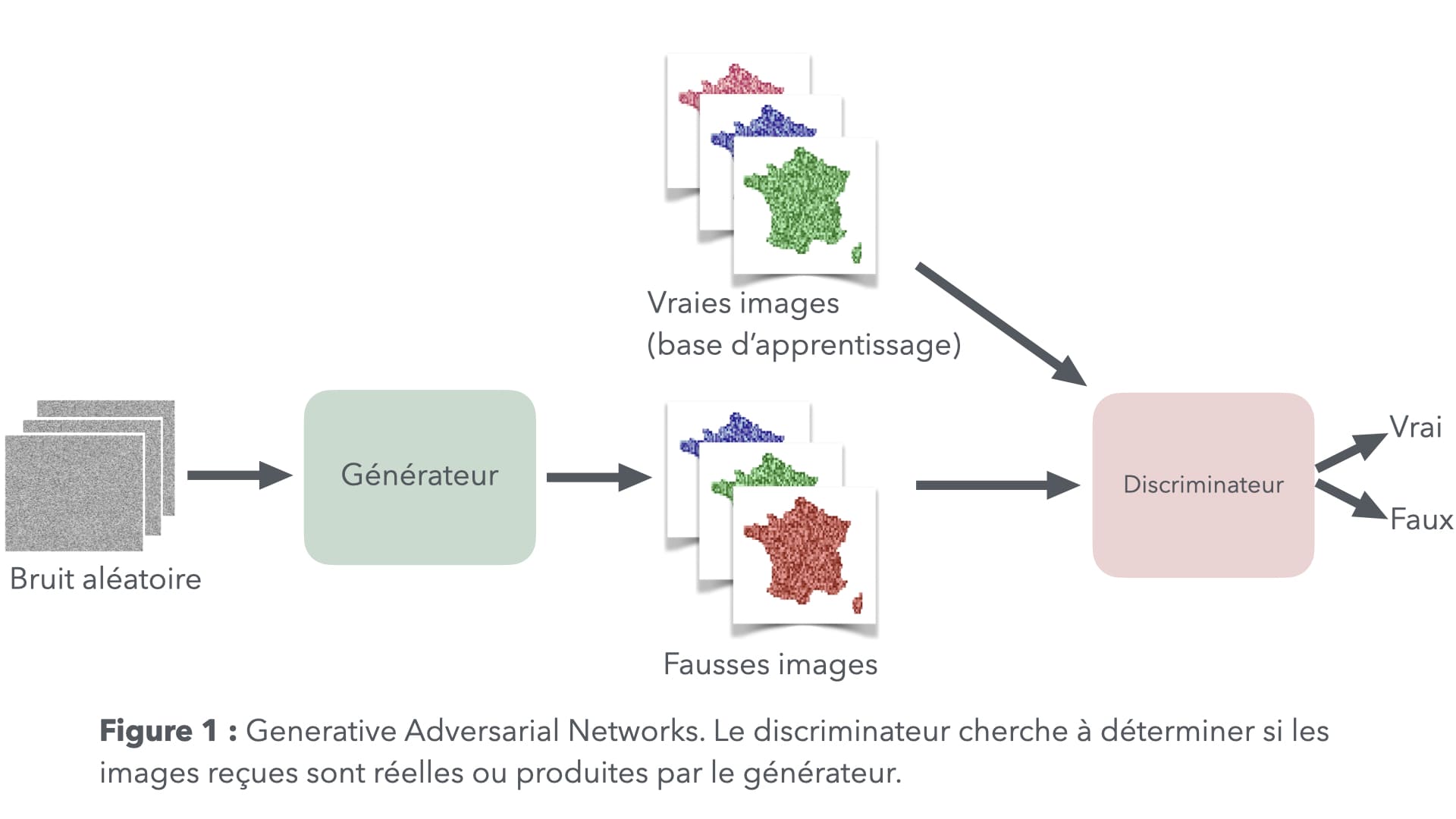
Le bloc génératif prend en entrée des simulations suivant une distribution arbitraire et leur fait subir des transformations complexes jusqu’à obtenir un résultat proche de ce que le phénomène que nous cherchons à reproduire peut engendrer. Dans le cas de la génération d’images, comme illustré sur le site This person does not exist, il s’agira par exemple de transformer un rectangle de pixels chaotique en une photo ressemblant à un individu réel. Le second bloc, le discriminateur, se voit présenter des images réelles et des images simulées. Charge à lui de déterminer lesquelles sont vraies et lesquelles sont fausses.
Le terme « adversarial » vient du fait que les deux réseaux apprennent l’un contre l’autre. Le générateur obtient une note d’autant meilleure qu’il parvient à tromper le discriminateur. Le discriminateur voit sa performance mesurée suivant sa capacité à bien identifier les observations artificielles. Ces deux parties s’amélioreront l’une et l’autre au fil de l’apprentissage, rendant le discriminateur plus exigeant et donc les productions de la partie génératrice de plus en plus crédibles.
La seconde classe de méthodes, dite par diffusion, prend d’une certaine façon le chemin inverse. Il s’agit de partir d’une observation réelle, puis de lui appliquer un bruit aléatoire. Toujours en reprenant l’exemple des images, nous poursuivons l’ajout du bruit jusqu’à ce que la photo d’origine soit complètement noyée. À l’issue de cette étape, nous obtenons donc une méthode pour transformer une information en bruit. Nous cherchons ensuite la transformation inverse. Si Xt désigne l’observation transformée après t étapes d’ajout de bruit, il s’agit à présent de déterminer la distribution de Xt-1 sachant Xt afin de pouvoir inverser la vapeur. Une fois que l’on a appris correctement cette transformation inverse, il s’agit ensuite de l’appliquer à des simulations de bruit blanc.
Dans les deux cas, nous aurons obtenu une procédure qui reconstitue la loi de probabilité du phénomène que nous souhaitons reproduire. La qualité de cette imitation dépendra également de celle des données qui auront servi à l’apprentissage. Vu sous cet angle, nous retombons sur la problématique de l’approche dite historique : la méthode générative, peu importe son degré de sophistication, ne reproduirait que ce qu’elle a déjà vu. La nouveauté serait somme toute très relative, puisqu’elle ne permettrait que de produire des situations similaires à l’ancien.
Générer des scénarios complexes
Au cours de notre présentation sommaire des méthodes génératives, nous avons occulté un élément important : la possibilité d’ajouter un contexte à la simulation. D’un point de vue mathématique, il s’agit d’approcher une distribution conditionnelle. Si nous souhaitons simuler les conséquences d’une inondation, nous pourrons intégrer les paramètres d’un scénario d’évolution du climat afin d’inciter l’IA à générer des situations intégrant notre vision du futur. Pour autant, où se situe la différence avec une approche plus naïve qui consisterait à ajuster un GLM, puis à l’utiliser pour projeter le risque en examinant son comportement lorsqu’on lui impose, en entrée, des hausses de températures, de précipitations, etc. ?
La différence se situe essentiellement dans la richesse de comportements que peuvent produire les méthodes d’IA générative. Là où le GLM impose une structure très rigide, très paramétrique dirait-on en statistique, le réseau de neurones profond possède une capacité d’adaptation bien plus grande. Il ne nécessite pas d’idée préconçue sur la façon dont les facteurs de risques pèsent sur le phénomène. Le modèle génératif est donc bien plus susceptible de générer des situations qui auraient pu nous échapper du fait de leur complexité. Si l’apprentissage a été effectué de façon satisfaisante, bien entendu.
Pour bénéficier des atouts des modèles génératifs, il faut donc d’abord s’assurer que cette condition est vérifiée. Dans le domaine, la clé du succès réside dans le nombre d’exemples et leur pertinence. Un problème de qualité et de quantité des données très familier aux actuaires, en somme. Pour ne considérer que la problématique de la quantité, la difficulté principale réside dans la rareté des phénomènes qu’on considère d’ordinaire en assurance.
Il peut paraître paradoxal de parler de rareté là où la tendance du moment est plutôt à souligner l’augmentation spectaculaire liée aux sinistres, notamment dans le domaine climatique. Il faut donc rappeler que, pour rester assurable, un risque ne doit pas entraîner des pertes importantes avec une trop grande fréquence. Sans quoi la prime d’assurance devient trop élevée pour le consommateur, sans même mentionner les problèmes de réserves qui pourraient être mises en péril par une forte volatilité. Partir de situations assurables et projeter leur évolution, c’est donc traiter des cas d’usage où les exemples sont peu nombreux. Si nous plaquons ce constat sur le contexte des risques émergents, la situation est même plus grave encore, car dans le domaine d’un nouveau risque, l’information est par essence réduite à peau de chagrin. Une situation à mettre en perspective avec celle de la génération de visages que nous mentionnions tout à l’heure, où l’apprentissage s’effectue sur des bases de données comptant plusieurs centaines de milliers, voire des millions, de photos.
Accélérer l’apprentissage, ajouter des connaissances
Comment concilier cette rareté avec la gourmandise des modèles génératifs ? Une piste prometteuse consiste à accélérer l’apprentissage en intégrant un certain nombre d’informations supplémentaires (théoriques ou empiriques).
Un exemple important concerne la rencontre de l’IA générative avec la théorie des valeurs extrêmes. Celle-ci est régulièrement convoquée, en actuariat, pour extrapoler un certain nombre de distributions (notamment dans l’analyse de la sévérité) au-delà de ce qui a été observé. Des théorèmes limites servent à justifier l’introduction de la loi de Pareto généralisée pour approcher la queue d’un vaste ensemble de lois de probabilités. De façon schématique, nous obtenons, à travers les quelques données disponibles, des indices pour prolonger au-delà du visible. Contrairement à une extrapolation arbitraire, celle-ci s’appuie sur un cadre théorique robuste, et sur la capacité de diagnostiquer la qualité de ce prolongement. Cette approche est notamment recommandée pour l’estimation des quantiles dits « extrêmes », tels que la value-at-risk à 99,5 %.
De récents travaux (1) ont ainsi proposé une adaptation des GAN à ce contexte. Dans de nombreuses applications en assurance, nous savons ainsi que la distribution du phénomène est dite « à queue lourde ». Nous pouvons ainsi tirer avantage de cette connaissance pour définir une structure de réseau GAN qui soit adaptée et puisse, ainsi, produire plus rapidement des outils capables de bien approcher la queue de distribution.
Dans le cadre du programme de recherche de la chaire CARE, nous travaillons également à intégrer l’avis d’experts, dans le cas de l’étude de différents risques naturels. Là encore, il s’agit d’accélérer l’apprentissage de la méthode génératrice en lui fournissant une sorte de connaissance de base, qui peut se formaliser comme un a priori bayésien. Cet aspect est notamment utile dans l’évaluation du coût économique de certains incidents. Un bon exemple concerne le retrait-gonflement des argiles, problématique de mieux en mieux documentée, mais où la sévérité du phénomène dépend de nombreux facteurs liés à la structure du bâtiment exposé, voire à sa géométrie. L’expertise dans ce domaine est de plus en plus riche, mais parfois difficilement accessible en vue d’une analyse quantitative. Elle se trouve en effet entre les mains d’experts de terrain, notamment du bâtiment, dont il faut être capable d’intégrer la connaissance. Ce travail de traduction, pour transporter cette connaissance dans le format quantitatif adapté aux études actuarielles, constitue la difficulté de l’exercice, mais aussi une perspective de progression importante.
Adapter l’IA aux contraintes de l’assurance
Les techniques d’IA génératives sont donc extrêmement prometteuses pour générer des scénarios nouveaux, permettant ainsi d’anticiper des situations qui n’ont pour l’heure pas été rencontrées et auxquelles l’assurance doit se préparer pour faire face à un paysage des risques en forte évolution. En la matière, il n’y a pas de miracle : pour qu’elles soient performantes, il est nécessaire de leur faire apprendre de la façon la plus efficace possible, sur des données pertinentes. La spécificité de l’assurance, nécessairement tournée vers l’analyse de phénomènes rares, rend l’analyse plus ardue. Il existe néanmoins des méthodes récentes pour accélérer la phase d’apprentissage, en tenant compte des propriétés connues des phénomènes considérés. Différents travaux de recherche engagés par la chaire CARE visent à optimiser la conception des réseaux de neurones utilisés pour générer ces scénarios, en s’adaptant à la nature du problème considéré et en intégrant les connaissances d’experts de ces domaines.
Si le problème est techniquement complexe, l’urgence de l’adaptation au changement climatique, en particulier dans le secteur assurantiel, nécessite de s’atteler au déploiement de ces techniques récentes. S’il ne faut pas survendre les bénéfices de telles méthodes ni oublier que de nombreuses inconnues sur les mécanismes sont à l’œuvre dans l’évolution du climat, parvenir à une quantification plus précise de l’impact de ces risques représente un atout considérable. Les actuaires ont un rôle clé à jouer dans la conception, l’appropriation et la diffusion de ces méthodes.
Références :
1 – On pourra notamment consulter Allouche, M., Girard, S., & Gobet, E. (2022). EV-GAN: Simulation of extreme events with ReLU neural networks. Journal of Machine Learning Research, 23(150), 1-39.